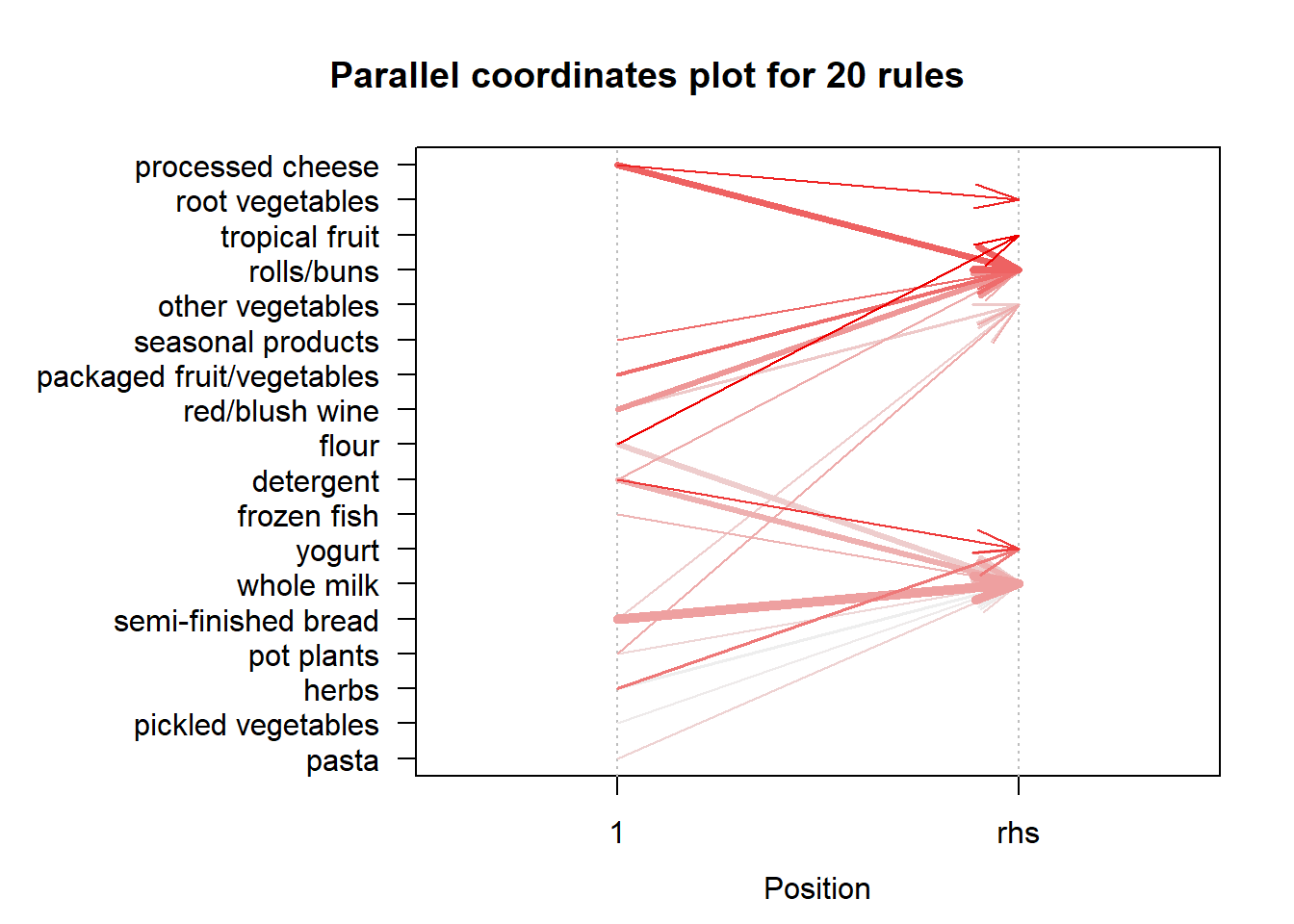
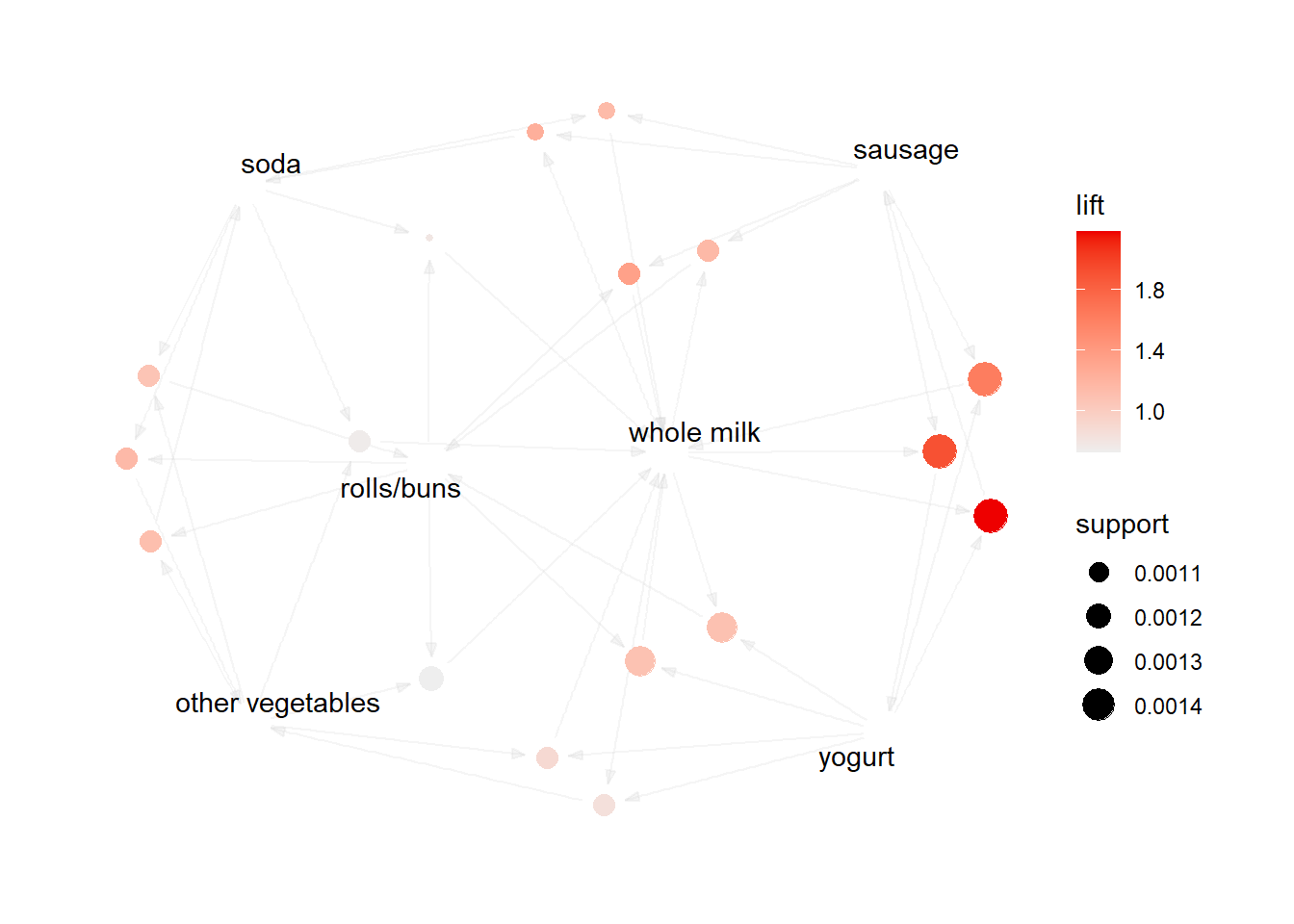
Apriori Algorithm Implementation in R using ‘arules’ library Association mining is usually done on transactions data from a retail market or from an online e-commerce store. Since most transactions data is large, the apriori algorithm makes it easier to find these patterns or rules quickly. Association Rules are widely used to analyze retail basket or transaction data, and are intended to identify strong rules discovered in transaction data using measures of interestingness, based on the concept of strong rules.
Apriori uses a “bottom up” approach, where frequent subsets are extended one item at a time (a step known as candidate generation), and groups of candidates are tested against the data. The algorithm terminates when no further successful extensions are found.
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(plyr)
------------------------------------------------------------------------------
You have loaded plyr after dplyr - this is likely to cause problems.
If you need functions from both plyr and dplyr, please load plyr first, then dplyr:
library(plyr); library(dplyr)
------------------------------------------------------------------------------
Attaching package: 'plyr'
The following objects are masked from 'package:dplyr':
arrange, count, desc, failwith, id, mutate, rename, summarise,
summarize
The following object is masked from 'package:purrr':
compact
Member_number Date itemDescription
Min. :1000 Length:38765 Length:38765
1st Qu.:2002 Class :character Class :character
Median :3005 Mode :character Mode :character
Mean :3004
3rd Qu.:4007
Max. :5000
sum(is.na(groceries))
[1] 0
Group all the items that were bought together by the same customer on the same date
The following objects are masked from 'package:tidyr':
expand, pack, unpack
Attaching package: 'arules'
The following object is masked from 'package:dplyr':
recode
The following objects are masked from 'package:base':
abbreviate, write
library(arulesViz)
# read the transactional dataset from a CSV file and convert it into a transaction objecttxn =read.transactions(file ="ItemList.csv", rm.duplicates =TRUE, # remove duplicate transactionsformat ="basket", # dataset is in basket format (each row represents a single transaction)sep =",", # CSV file is comma-separatedcols =1) # transaction IDs are stored in the first column of the CSV file
distribution of transactions with duplicates:
items
1 2 3 4
662 39 5 1
print(txn)
transactions in sparse format with
14964 transactions (rows) and
168 items (columns)
The first line of output shows the distribution of transactions by item. In this case, there are four items (items 1, 2, 3, and 4), and the numbers indicate how many transactions in the dataset contain each item. For example, there are 662 transactions that contain item 1, 39 transactions that contain item 2, 5 transactions that contain item 3, and 1 transaction that contains item 4. This information is useful for understanding the frequency of different items in the dataset and identifying which items are most commonly associated with each other.
The second line of output shows the total number of transactions in the dataset and the number of unique items that appear in those transactions. Specifically, there are 14964 transactions (rows) and 168 unique items (columns). The transactions are in sparse format, meaning that the majority of the entries in the transaction matrix are zero (i.e., most transactions do not contain most of the items). This format is used to save memory when working with large datasets that have many items.
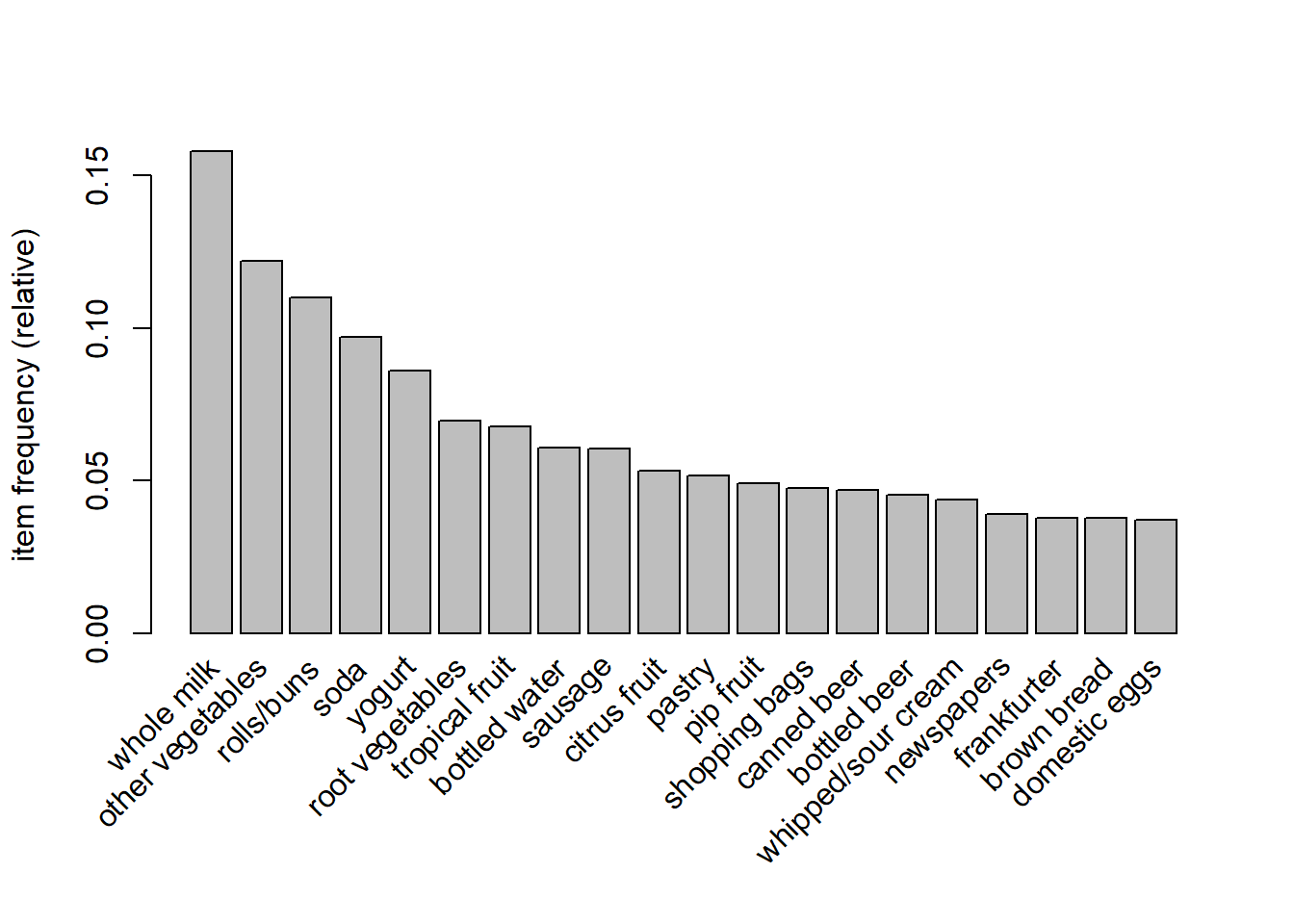
Most Frequent Products
itemFrequencyPlot(txn, topN =20)
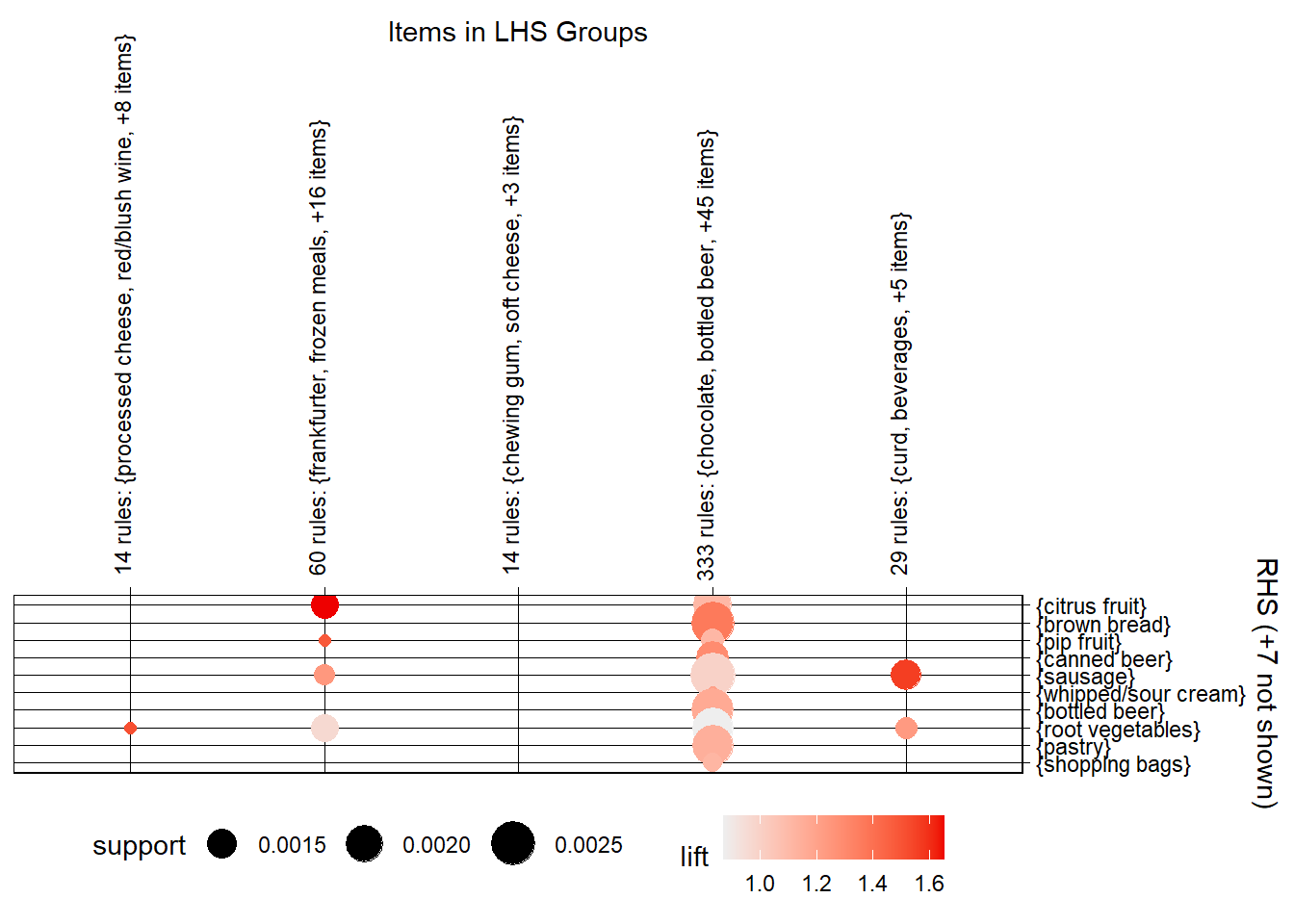
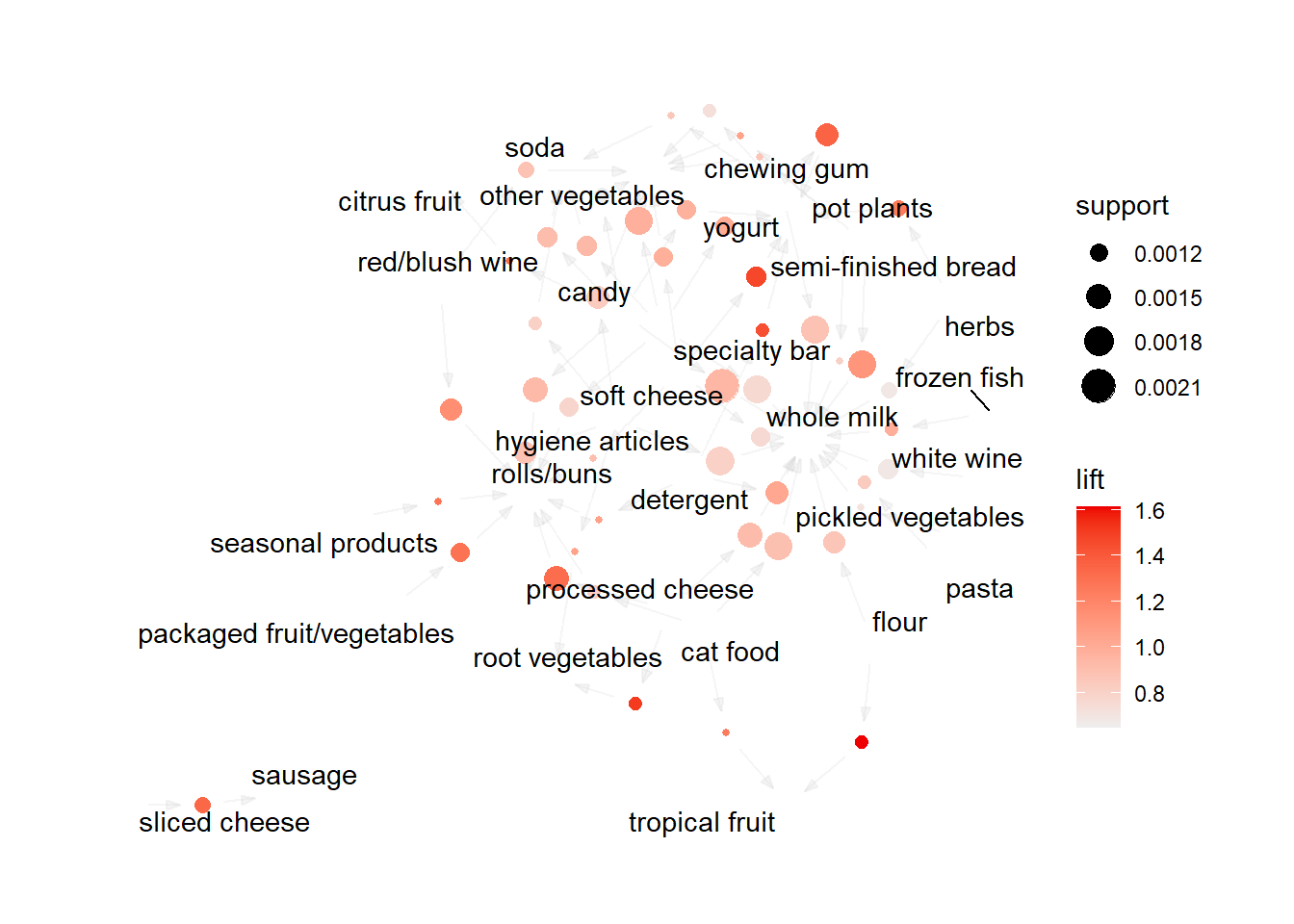
Apriori Algorithm The apriori() generates the most relevent set of rules from a given transaction data. It also shows the support, confidence and lift of those rules. These three measure can be used to decide the relative strength of the rules. So what do these terms mean?
Lets consider the rule {X → Y} in order to compute these metrics.
basket_rules <-apriori(txn, parameter =list(minlen =2, # Minimum number of items in a rule (in this case, 2)sup =0.001, # Minimum support threshold (a rule must be present in at least 0.1% of transactions)conf =0.05, # Minimum confidence threshold (rules must have at least 5% confidence)target ="rules"# Specifies that we want to generate association rules ))
The apriori function takes several parameters, including the transaction dataset (txn) and a list of parameters (parameter) that control the behavior of the algorithm. The minlen parameter sets the minimum number of items in a rule to 2, which means that the algorithm will only consider rules that involve at least 2 items. The sup parameter sets the minimum support threshold to 0.001, which means that a rule must be present in at least 0.1% of transactions in order to be considered significant. The conf parameter sets the minimum confidence threshold to 0.05, which means that a rule must have at least 5% confidence (i.e., be correct at least 5% of the time) to be considered significant. Finally, the target parameter specifies that we want to generate association rules rather than just frequent itemsets.
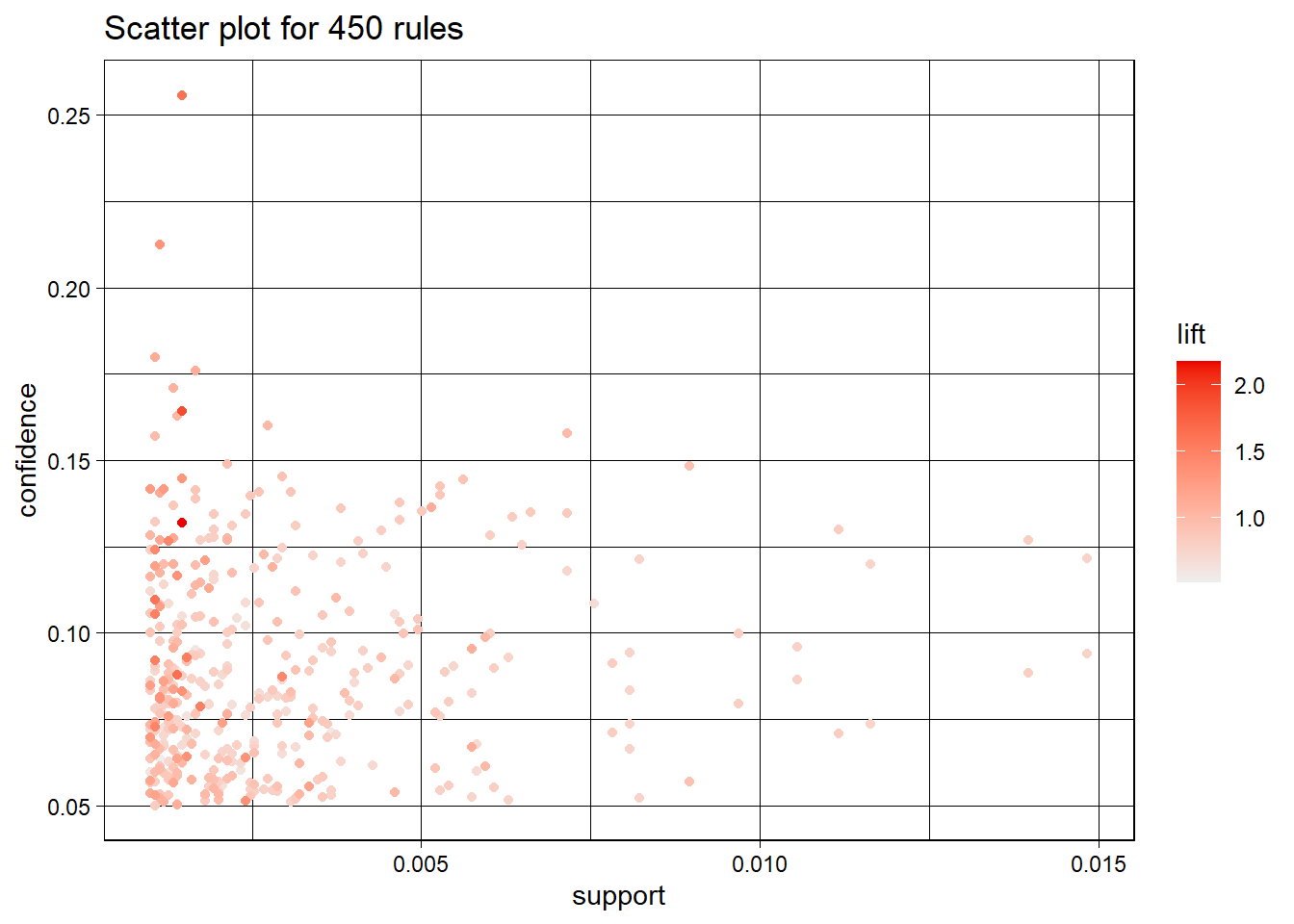
Total rules generated
print(length(basket_rules))
[1] 450
summary(basket_rules)
set of 450 rules
rule length distribution (lhs + rhs):sizes
2 3
423 27
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 2.00 2.00 2.06 2.00 3.00
summary of quality measures:
support confidence coverage lift
Min. :0.001002 Min. :0.05000 Min. :0.005346 Min. :0.5195
1st Qu.:0.001270 1st Qu.:0.06397 1st Qu.:0.015972 1st Qu.:0.7673
Median :0.001938 Median :0.08108 Median :0.023590 Median :0.8350
Mean :0.002760 Mean :0.08759 Mean :0.033723 Mean :0.8859
3rd Qu.:0.003341 3rd Qu.:0.10482 3rd Qu.:0.043705 3rd Qu.:0.9601
Max. :0.014836 Max. :0.25581 Max. :0.157912 Max. :2.1831
count
Min. : 15.0
1st Qu.: 19.0
Median : 29.0
Mean : 41.3
3rd Qu.: 50.0
Max. :222.0
mining info:
data ntransactions support confidence
txn 14964 0.001 0.05
call
apriori(data = txn, parameter = list(minlen = 2, sup = 0.001, conf = 0.05, target = "rules"))
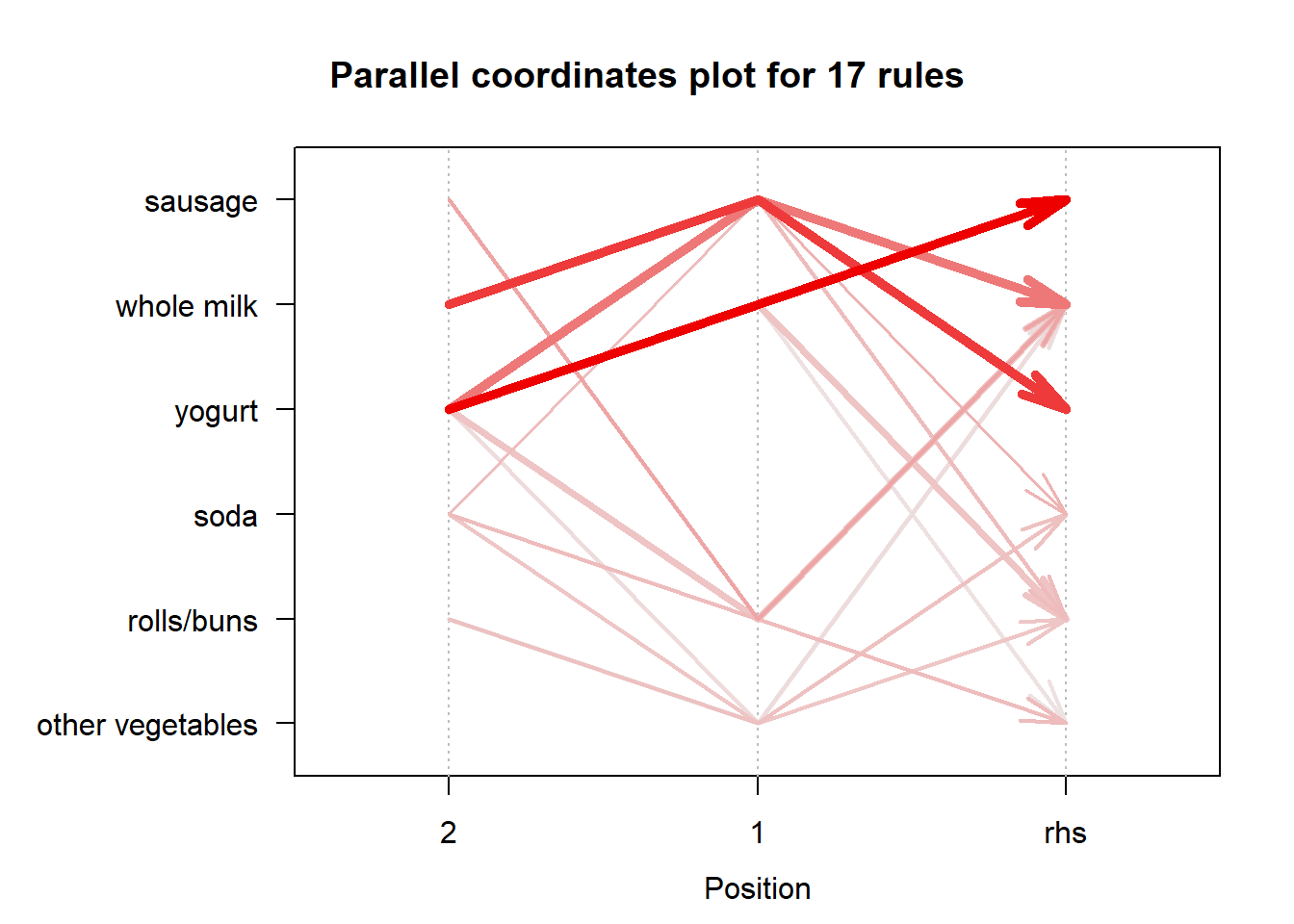
set of 17 rules
rule length distribution (lhs + rhs):sizes
3
17
Min. 1st Qu. Median Mean 3rd Qu. Max.
3 3 3 3 3 3
summary of quality measures:
support confidence coverage lift
Min. :0.001002 Min. :0.1018 Min. :0.005346 Min. :0.7214
1st Qu.:0.001136 1st Qu.:0.1172 1st Qu.:0.008086 1st Qu.:0.8897
Median :0.001136 Median :0.1269 Median :0.008955 Median :1.1081
Mean :0.001207 Mean :0.1437 Mean :0.008821 Mean :1.1794
3rd Qu.:0.001337 3rd Qu.:0.1642 3rd Qu.:0.010559 3rd Qu.:1.2297
Max. :0.001470 Max. :0.2558 Max. :0.011160 Max. :2.1831
count
Min. :15.00
1st Qu.:17.00
Median :17.00
Mean :18.06
3rd Qu.:20.00
Max. :22.00
mining info:
data ntransactions support confidence
txn 14964 0.001 0.1
call
apriori(data = txn, parameter = list(minlen = 3, sup = 0.001, conf = 0.1, target = "rules"))