The basic idea behind k-means clustering consists of defining clusters so that the total intra-cluster variation (known as total within-cluster variation) is minimized. There are several k-means algorithms available. The standard algorithm is the Hartigan-Wong algorithm (Hartigan and Wong 1979), which defines the total within-cluster variation as the sum of squared distances Euclidean distances between items and the corresponding centroid
The USArrests dataset is a built-in dataset in R that contains data on crime rates (number of arrests per 100,000 residents) in the United States in 1973. The dataset has 50 observations, corresponding to the 50 US states, and 4 variables:
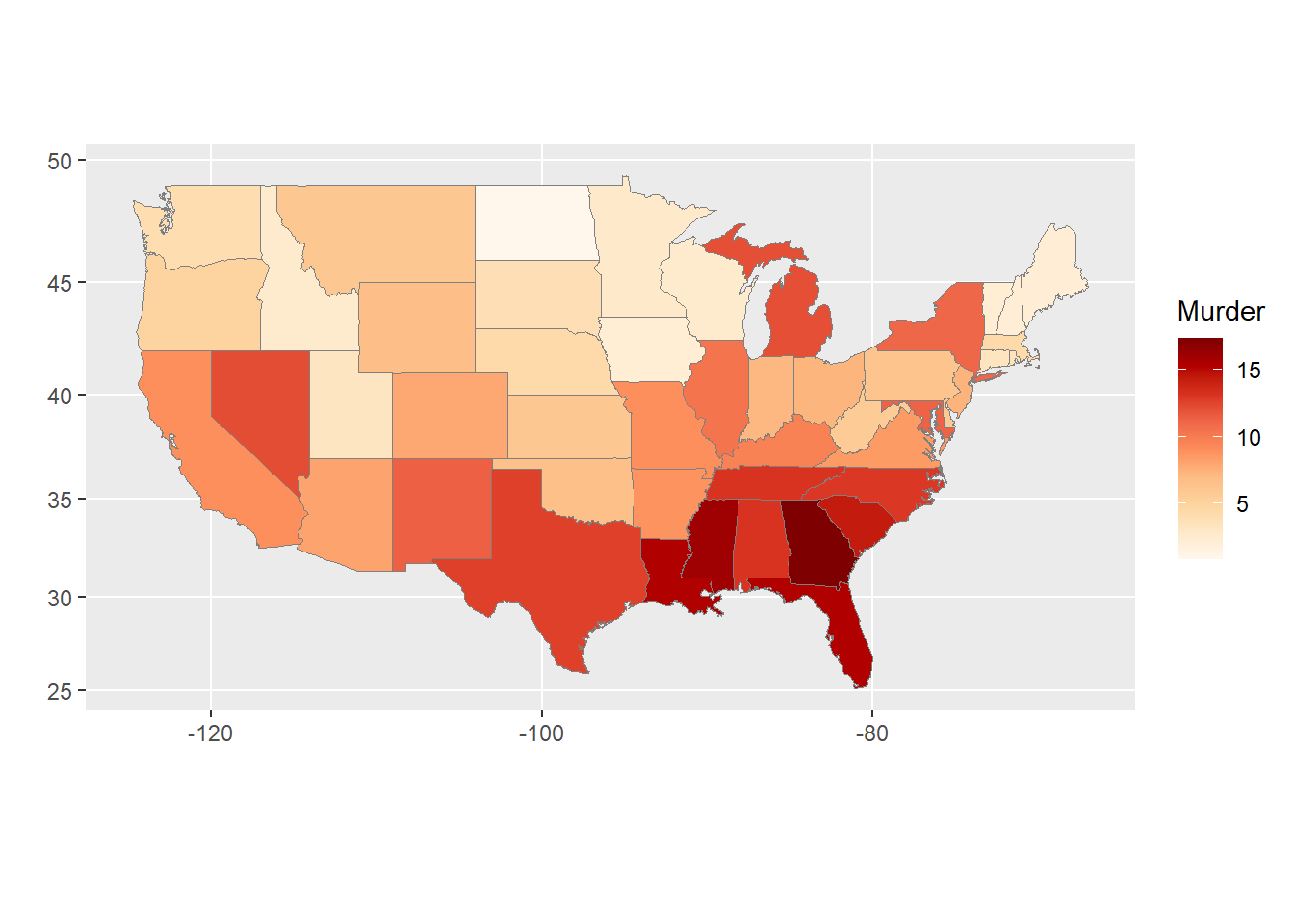
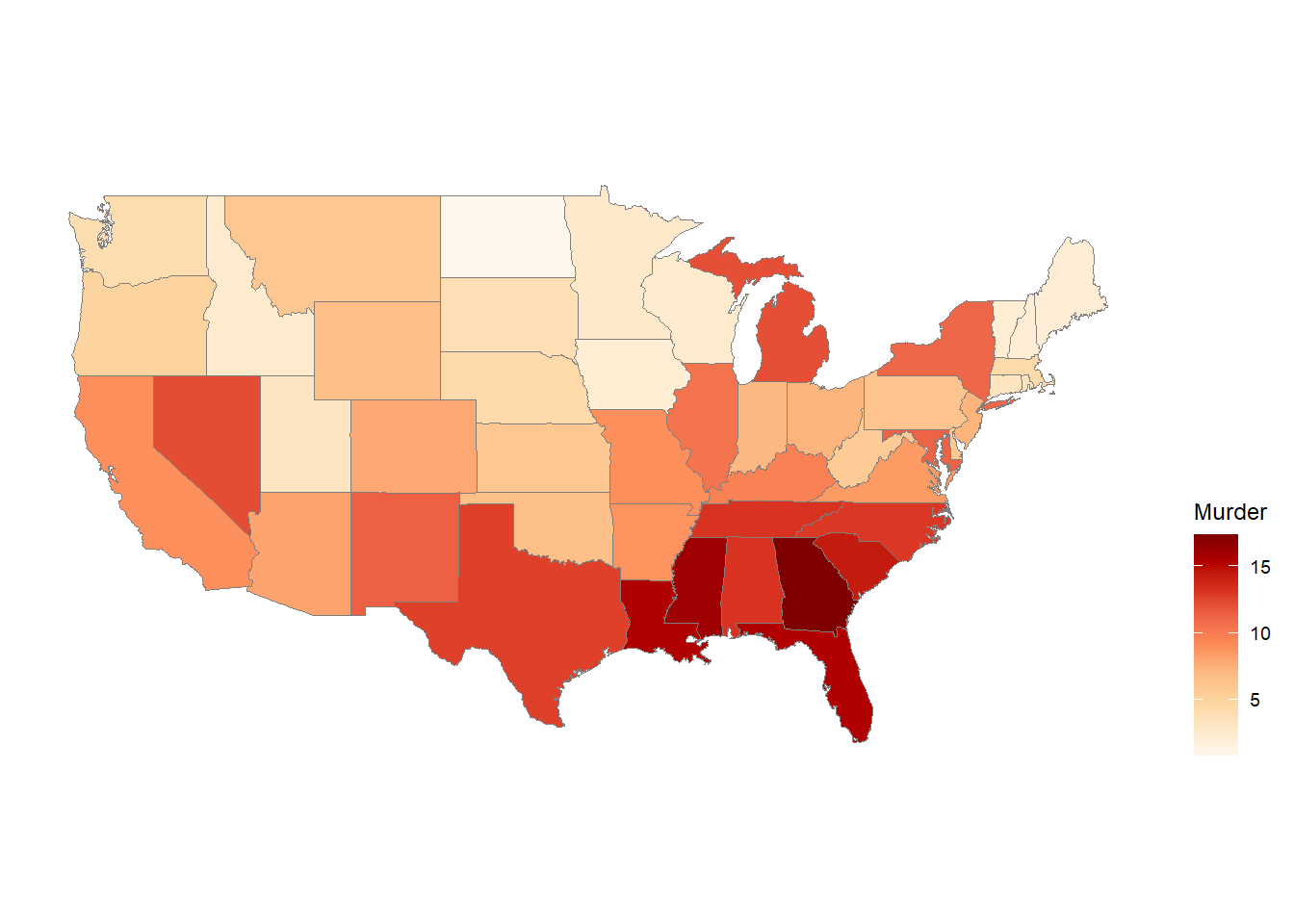
Murder: Murder arrests (number of arrests for murder per 100,000 residents).
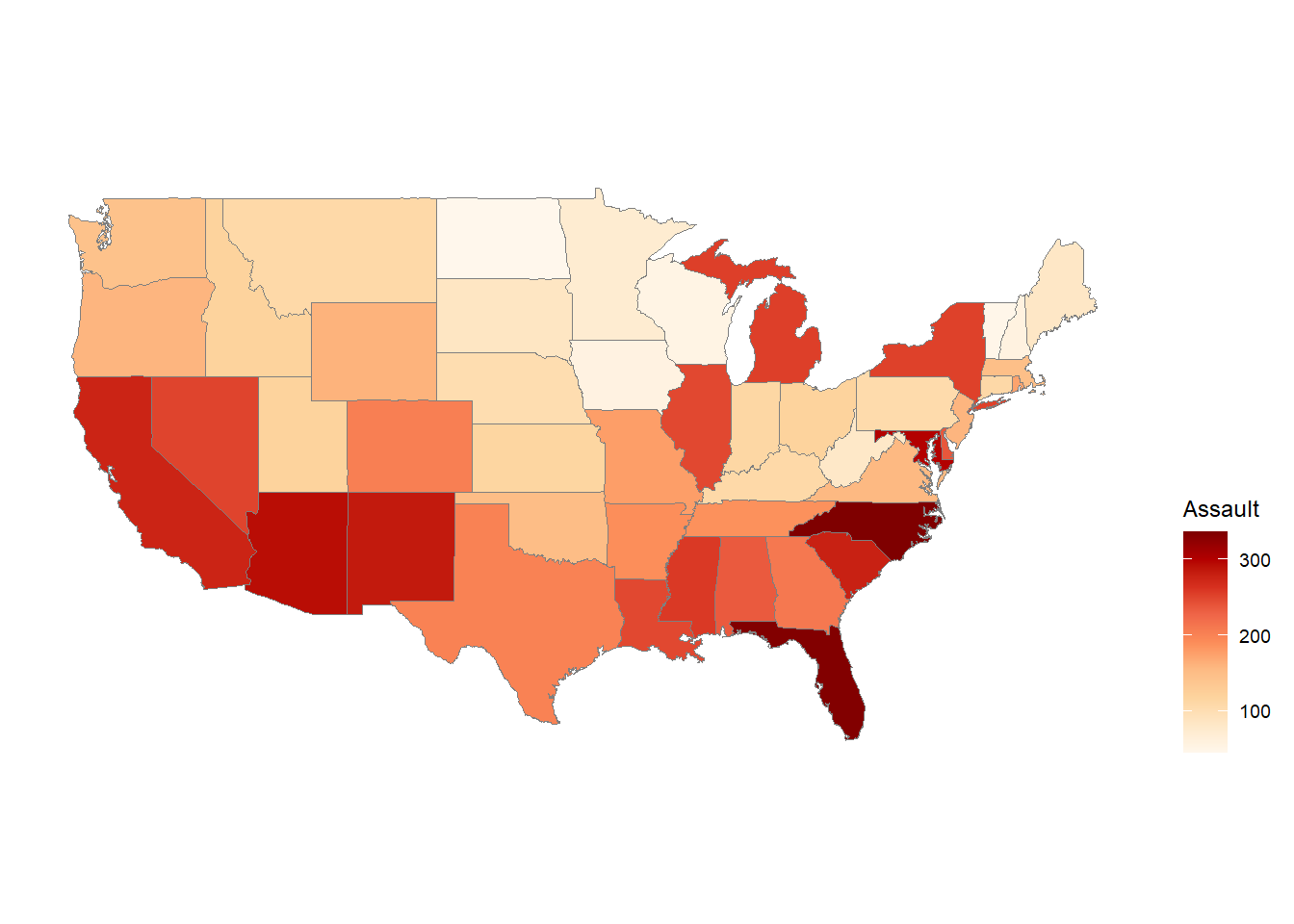
Assault: Assault arrests (number of arrests for assault per 100,000 residents).
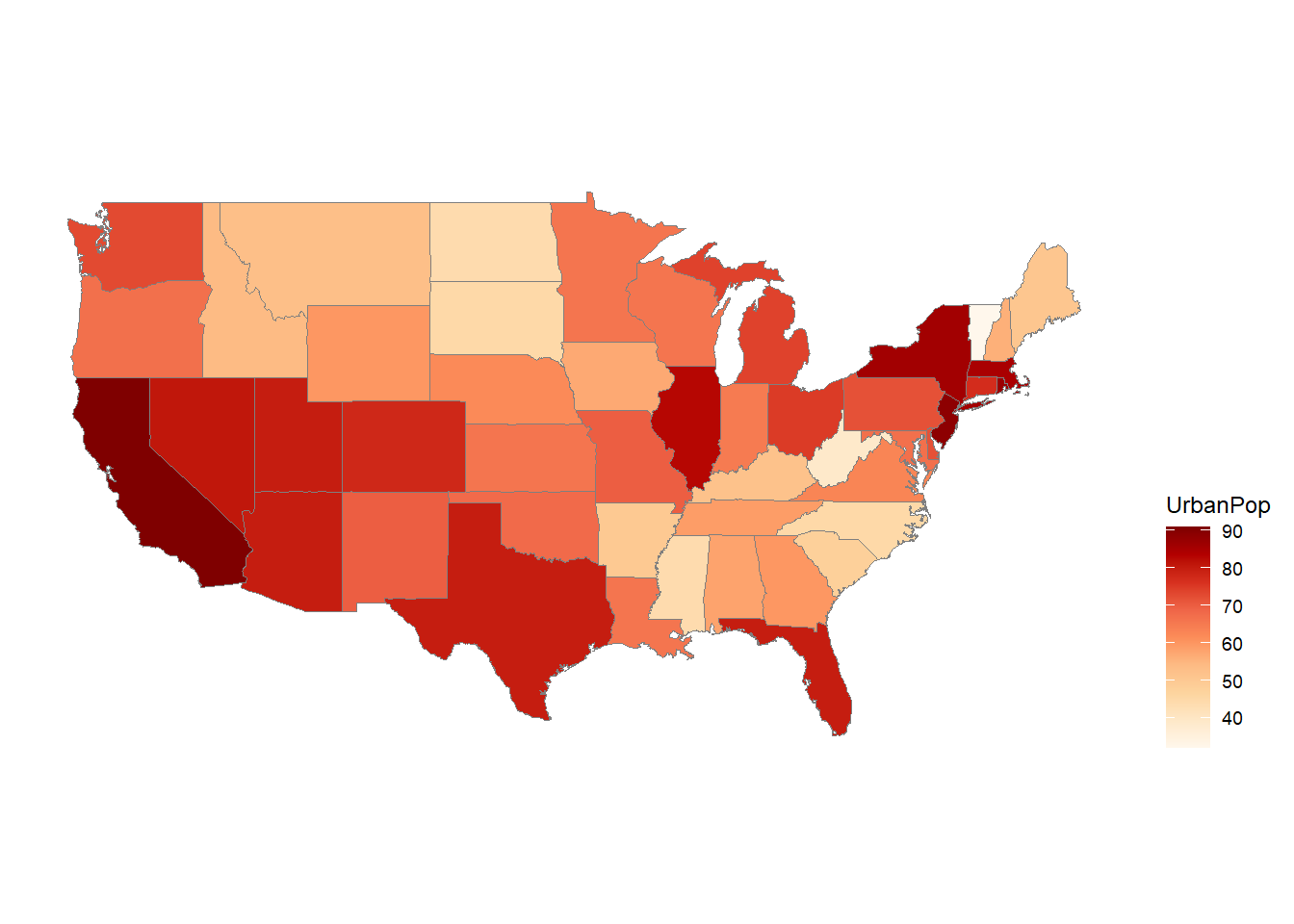
UrbanPop: Urban population (percentage of the population living in urban areas).
Rape: Rape arrests (number of arrests for rape per 100,000 residents).
The states_map <- map_data("state") code is used to create a dataframe that contains map data for the 50 states in the United States.
The map_data() function is from the ggplot2 package, and it returns a dataframe that contains latitude and longitude coordinates for the boundaries of each state, along with additional information that can be used to plot the map.
The argument to the map_data() function is the name of the region for which to retrieve the map data. In this case, the argument is "state", which indicates that we want map data for the 50 states in the US.
The resulting states_map dataframe contains the following columns:
long: A vector of longitudes representing the boundaries of the state.
lat: A vector of latitudes representing the boundaries of the state.
group: An integer indicating the group to which each point belongs. This is used to group the points together when plotting the map.
order: An integer indicating the order in which the points should be plotted.
region: A character string indicating the name of the state.
subregion: A character string indicating the name of a subregion within the state, if applicable. This is usually NA for the state maps.
states_map <-map_data("state")head(states_map)
long lat group order region subregion
1 -87.46201 30.38968 1 1 alabama <NA>
2 -87.48493 30.37249 1 2 alabama <NA>
3 -87.52503 30.37249 1 3 alabama <NA>
4 -87.53076 30.33239 1 4 alabama <NA>
5 -87.57087 30.32665 1 5 alabama <NA>
6 -87.58806 30.32665 1 6 alabama <NA>
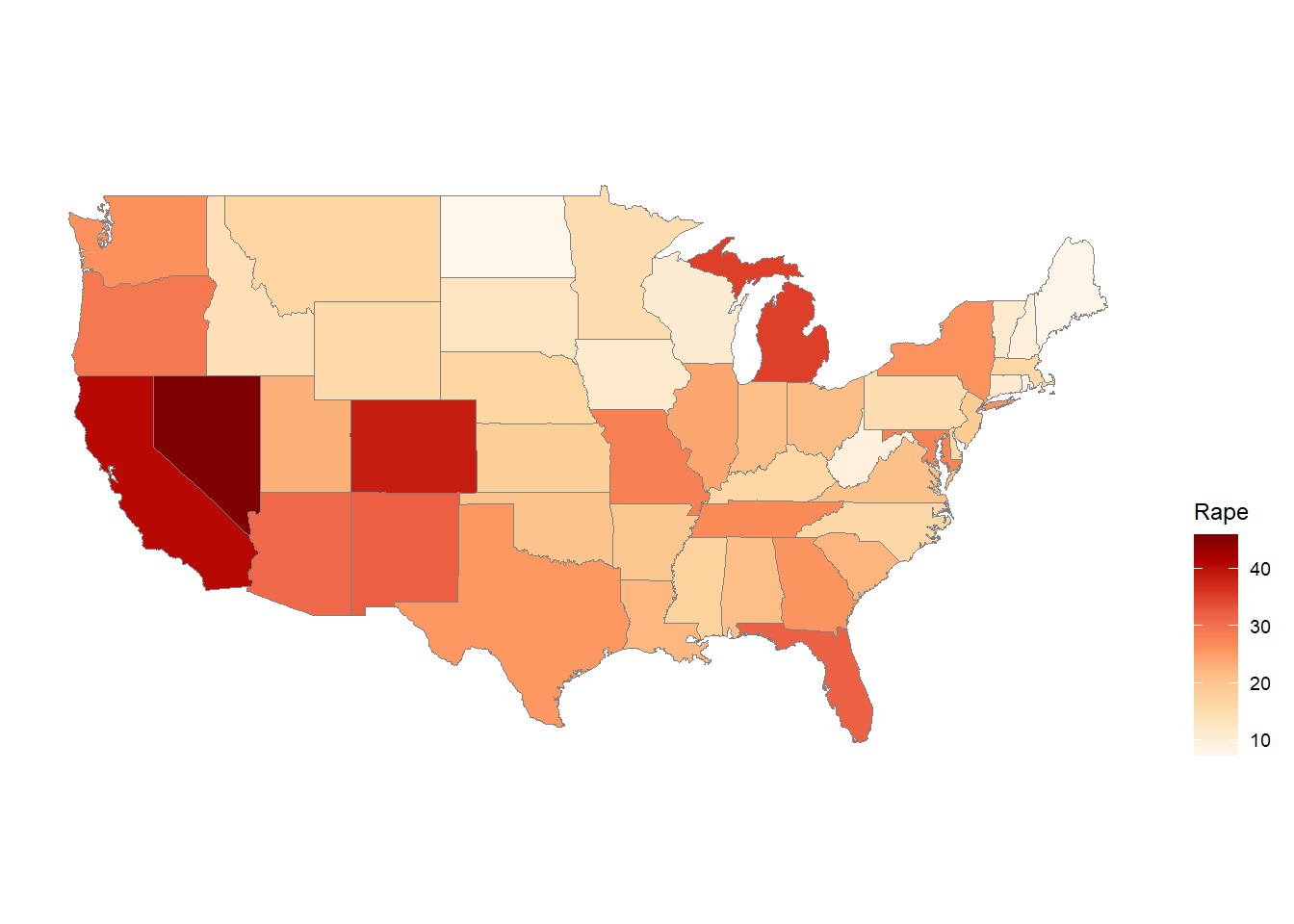
The code library(ggiraphExtra) loads the ggiraphExtra package, which extends the functionality of the ggplot2 package to allow for interactive graphics in R.
The ggChoropleth() function is from the ggiraphExtra package and is used to create a choropleth map in which each state is colored according to its value of a specified variable.
The first argument to ggChoropleth() is the data frame containing the data to be plotted, which is crime in this case.
The second argument is the aes() function, which is used to map variables in the data frame to visual properties of the plot. The fill aesthetic is used to specify that the color of each state should be determined by the value of the Murder variable in the crime data frame. The map_id aesthetic is used to specify that each state should be identified by its name, which is found in the state variable in the crime data frame.
The third argument is the map argument, which specifies the data frame containing the map data. In this case, the states_map data frame is used, which was created earlier using the map_data() function.
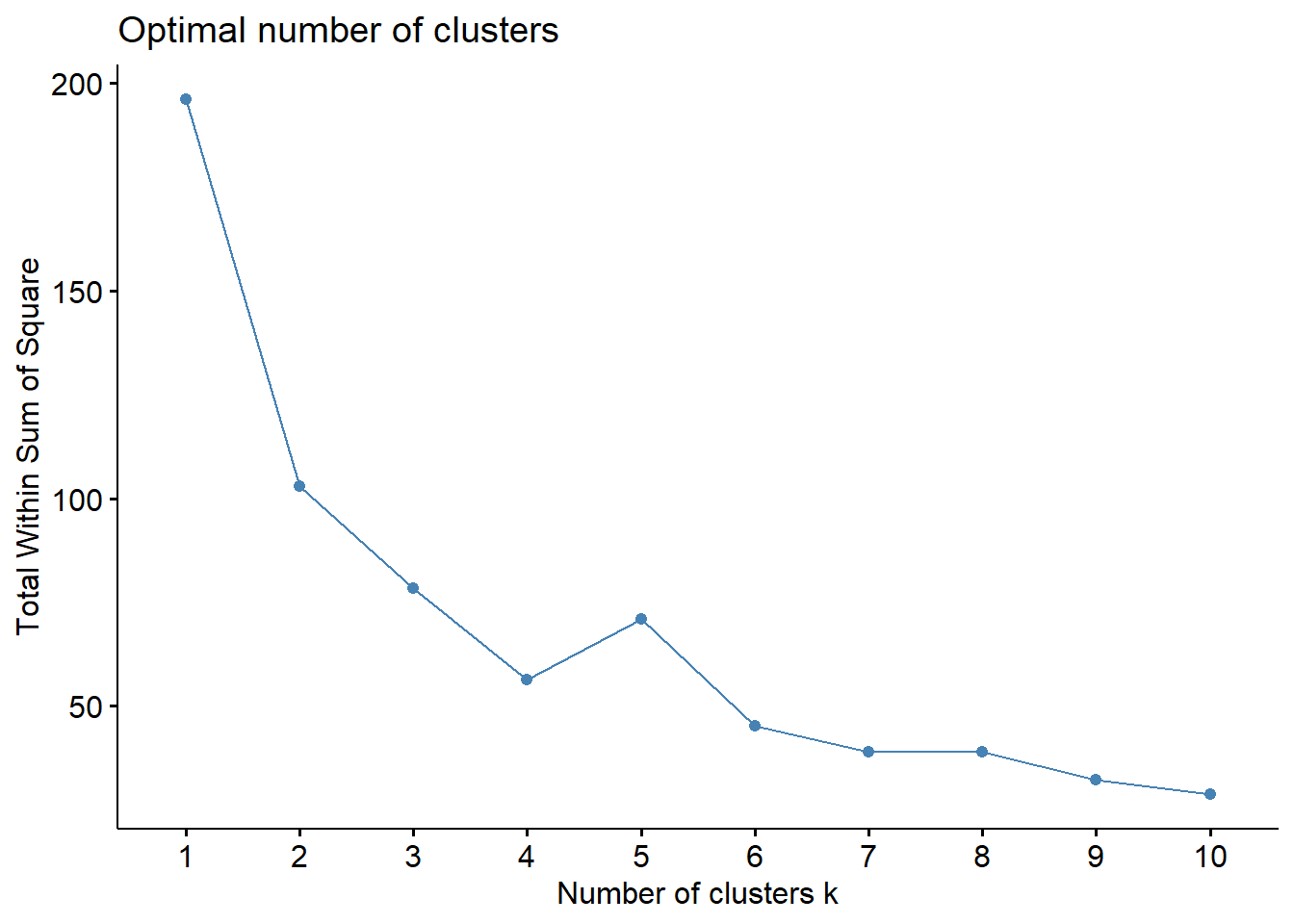
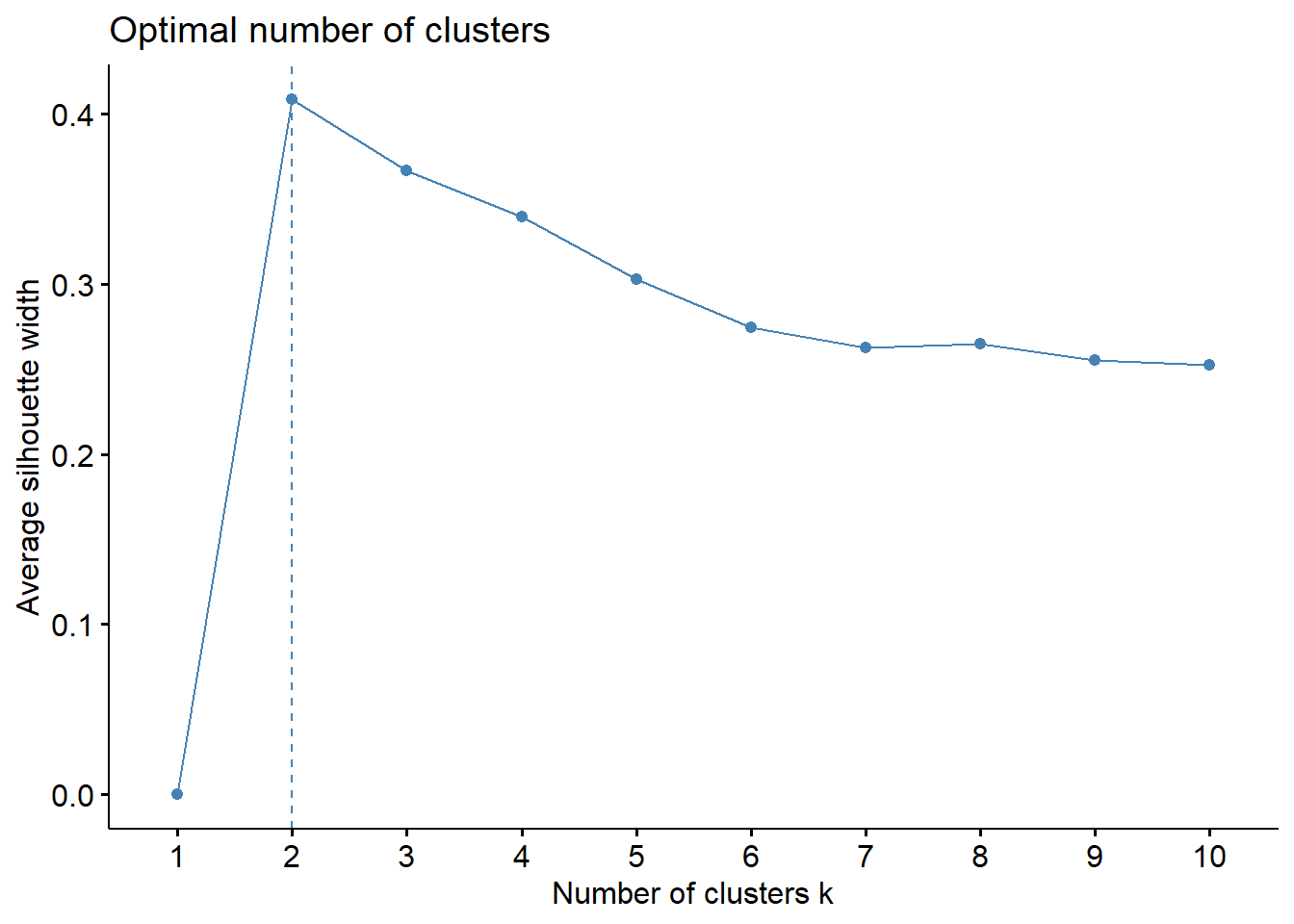
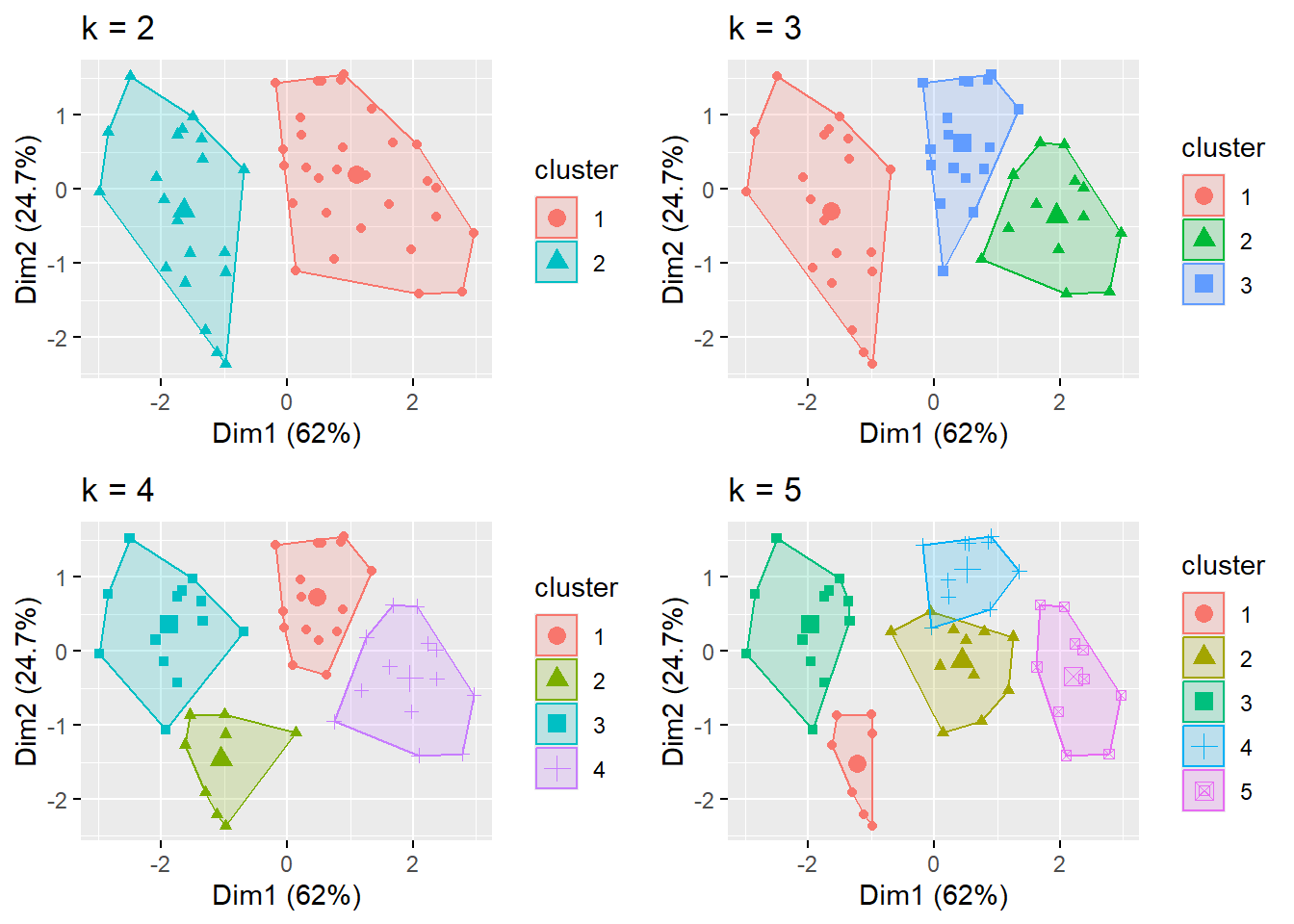
This code uses the fviz_nbclust() function from the factoextra package in R to determine the optimal number of clusters to use in a K-means clustering analysis.
The first argument of fviz_nbclust() is the data frame df that contains the variables to be used in the clustering analysis.
The second argument is the clustering function kmeans that specifies the algorithm to be used for clustering.
The third argument method specifies the method to be used to determine the optimal number of clusters. In this case, two methods are used:
"wss": Within-cluster sum of squares. This method computes the sum of squared distances between each observation and its assigned cluster center, and then adds up these values across all clusters. The goal is to find the number of clusters that minimize the within-cluster sum of squares.
"silhouette": Silhouette width. This method computes a silhouette width for each observation, which measures how similar the observation is to its own cluster compared to other clusters. The goal is to find the number of clusters that maximize the average silhouette width across all observations.
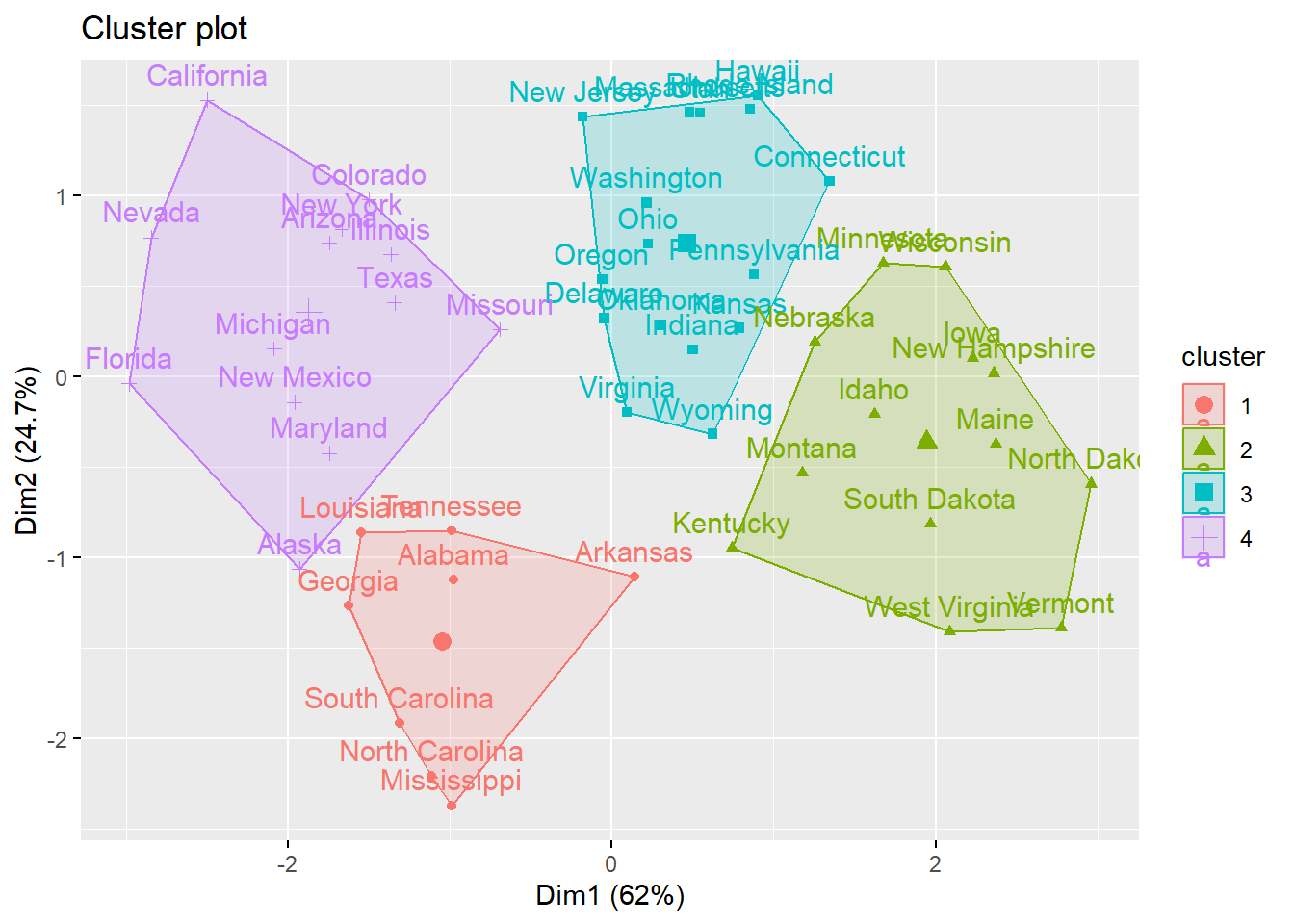
Let’s run unsupervised clustering given k=4
# Compute k-means with k = 4set.seed(123)km.res <-kmeans(df, 4, nstart =25)
As the final result of k-means clustering result is sensitive to the random starting assignments, we specify nstart = 25. This means that R will try 25 different random starting assignments and then select the best results corresponding to the one with the lowest within cluster variation. The default value of nstart in R is one. But, it’s strongly recommended to compute k-means clustering with a large value of nstart such as 25 or 50, in order to have a more stable result.
Print the result
# Print the resultsprint(km.res)
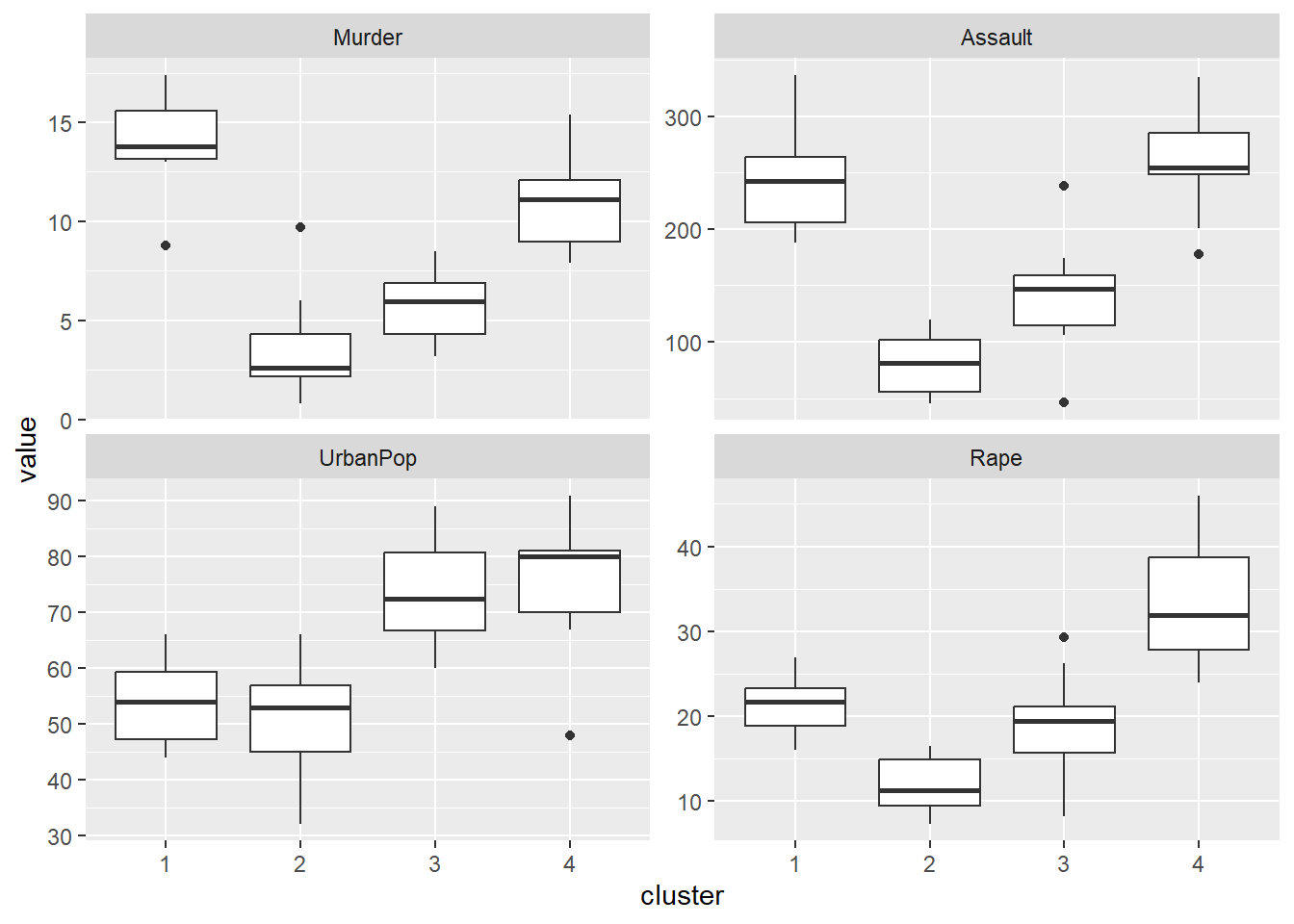
K-means clustering with 4 clusters of sizes 8, 13, 16, 13
Cluster means:
Murder Assault UrbanPop Rape
1 1.4118898 0.8743346 -0.8145211 0.01927104
2 -0.9615407 -1.1066010 -0.9301069 -0.96676331
3 -0.4894375 -0.3826001 0.5758298 -0.26165379
4 0.6950701 1.0394414 0.7226370 1.27693964
Clustering vector:
Alabama Alaska Arizona Arkansas California
1 4 4 1 4
Colorado Connecticut Delaware Florida Georgia
4 3 3 4 1
Hawaii Idaho Illinois Indiana Iowa
3 2 4 3 2
Kansas Kentucky Louisiana Maine Maryland
3 2 1 2 4
Massachusetts Michigan Minnesota Mississippi Missouri
3 4 2 1 4
Montana Nebraska Nevada New Hampshire New Jersey
2 2 4 2 3
New Mexico New York North Carolina North Dakota Ohio
4 4 1 2 3
Oklahoma Oregon Pennsylvania Rhode Island South Carolina
3 3 3 3 1
South Dakota Tennessee Texas Utah Vermont
2 1 4 3 2
Virginia Washington West Virginia Wisconsin Wyoming
3 3 2 2 3
Within cluster sum of squares by cluster:
[1] 8.316061 11.952463 16.212213 19.922437
(between_SS / total_SS = 71.2 %)
Available components:
[1] "cluster" "centers" "totss" "withinss" "tot.withinss"
[6] "betweenss" "size" "iter" "ifault"
The printed output displays: the cluster means or centers: a matrix, which rows are cluster number (1 to 4) and columns are variables the clustering vector: A vector of integers (from 1:k) indicating the cluster to which each point is allocated
If you want to add the point classifications to the original data, use this:
str(km.res)
List of 9
$ cluster : Named int [1:50] 1 4 4 1 4 4 3 3 4 1 ...
..- attr(*, "names")= chr [1:50] "Alabama" "Alaska" "Arizona" "Arkansas" ...
$ centers : num [1:4, 1:4] 1.412 -0.962 -0.489 0.695 0.874 ...
..- attr(*, "dimnames")=List of 2
.. ..$ : chr [1:4] "1" "2" "3" "4"
.. ..$ : chr [1:4] "Murder" "Assault" "UrbanPop" "Rape"
$ totss : num 196
$ withinss : num [1:4] 8.32 11.95 16.21 19.92
$ tot.withinss: num 56.4
$ betweenss : num 140
$ size : int [1:4] 8 13 16 13
$ iter : int 2
$ ifault : int 0
- attr(*, "class")= chr "kmeans"
km.res$cluster
Alabama Alaska Arizona Arkansas California
1 4 4 1 4
Colorado Connecticut Delaware Florida Georgia
4 3 3 4 1
Hawaii Idaho Illinois Indiana Iowa
3 2 4 3 2
Kansas Kentucky Louisiana Maine Maryland
3 2 1 2 4
Massachusetts Michigan Minnesota Mississippi Missouri
3 4 2 1 4
Montana Nebraska Nevada New Hampshire New Jersey
2 2 4 2 3
New Mexico New York North Carolina North Dakota Ohio
4 4 1 2 3
Oklahoma Oregon Pennsylvania Rhode Island South Carolina
3 3 3 3 1
South Dakota Tennessee Texas Utah Vermont
2 1 4 3 2
Virginia Washington West Virginia Wisconsin Wyoming
3 3 2 2 3
Create a new data frame including cluster information